はじめに
Auto RecoveryとAuto Healing。
どちらもEC2インスタンスに障害があった時に何かしらの対応を取ってくれるものですが、考え方は大きく異なります。両者の違いを、いくつかの観点から読み解いていきます。
- 実行主体
- 実行契機
- 発動時の挙動
- 発動後も保持されるデータ
1.Auto Recoveryとは
CloudWatchアラームのアクションの一つとして設定するもので、物理ホストに障害があった場合に仮想マシンをマイグレーションしてくれるものです。
[インスタンスの復旧]
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-instance-recover.html
1.1.実行主体
CloudWatchアラームです。
Auto Recoveryの対象としたいEC2インスタンスに個々に設定する必要があります。
EC2の停止や再起動のアクションを行う場合と異なり、CloudWatchアラームに対してロール(サービスにリンクするロール)の設定は不要です。
1.2.実行契機
EC2インスタンスのメトリクスStatusCheckFailed_Systemでステータスチェックの失敗を検知した場合に実行されます。
どの程度失敗を検知した際にアクションを実行するかの閾値は、ユーザ側で細かく設定可能です。
ステータスチェックに失敗するケースとしては以下のようなものがあります。
- ネットワーク接続の喪失
- システム電源の喪失
- 物理ホストのソフトウェアの問題
- ネットワーク到達可能性に影響する、物理ホスト上のハードウェアの問題
1.3.発動時の挙動
異なる物理ホストに仮想マシンをマイグレーションします。
仮想マシン上のOSはマイグレーション時に再起動を伴います。
EC2インスタンスとして再起動を伴うか、停止起動のイベントが記録されるかは、公式の情報としては確認できませんでした。
1.4.発動後も保持されるデータ
仮想マシンとしては各種情報を引き継ぎます。
- インスタンスID
- プライベートIPアドレス
- パブリックIPアドレス
- Elastic IPアドレス
- メタデータ
また、マイグレーション後も同一のEBSボリュームがアタッチされたままのため、ディスク上のデータも保持されます。ディスクに書き込まれずにメモリ上にのみ存在していたデータはOSの再起動に伴いロストします。
1.5.注意点
発動には条件があります。
- インスタンスタイプが特定のものであること
- インスタンスストアボリュームを使用していないこと
- テナンシーがデフォルトかハードウェア占有インスタンスであること
また、マイグレーション先の物理ホストに空きが無い場合など、復旧処理に失敗することもあります。
2.Auto Healingとは
そういった名称の機能というよりは、Auto Scalingによって「指定したインスタンスの最小台数を維持すること」のデザインパターンをAuto Healingと呼称することが多いです。

[AWS Black Belt Online Seminar 2017 Auto Scaling]
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-online-seminar-2017-auto-scaling/15
(ちなみにOpsWorksにおいてもAuto Healingというワードが出てきますが、本記事で扱っているEC2のAuto Healingとは別物です。)
自動ヒーリングを使用した、失敗したインスタンスの置き換え
2.1.実行主体
Auto Scalingのコンポーネントのうちの1つである、Auto Scalingグループです。
Auto Scaling のコンポーネント
- Auto Scalingグループ
- Auto Scalingの管理対象となるEC2インスタンスの集合体
- 起動設定
- Auto Scalingにより作成されるインスタンスのベースを定義するもの
- スケーリングプラン
- Auto Scalingグループのインスタンスのスケールのきっかけ、ルールなどを定義するもの
ユーザに変わってインスタンスを作成したり削除したりするため、サービスリンクロールが必要です。
Amazon EC2 Auto Scaling のサービスにリンクされたロール
2.2.実行契機
Auto Scalingのヘルスチェックに失敗した際に発動します。
[Auto Scaling インスタンスのヘルスチェック]
https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/healthcheck.html
観点としては3つあります。
- EC2インスタンスのステータスチェック
- ELBのヘルスチェック
- カスタムヘルスチェック
2.1.1.EC2インスタンスのステータスチェック
デフォルトで有効になっており、無効化することはできません。以下2種の観点に大別されます。
- a.インスタンスステータス
- b.システムステータス
似た用語が出てくるため、ここでは以下のように置き換えて表現します。
- a.インスタンスの稼動状態
- b.ステータスチェック
前者a.は「running」「stopped」などの状態を表すものです。running以外のステータスに遷移した場合、Auto Scalingのヘルスチェックでは異常ありとみなされます。後者b.はさらに2つに細分化され、両方のチェックに合格した場合に「OK」1つ以上でエラーが検知されれば「impaired」となります。
- b.ステータスチェック
- インスタンスステータスチェック:物理ホストより上のレイヤの障害をモニタリング
- システムステータスチェック:物理ホスト・ネットワーク層の障害をモニタリング
「imapaired」が検出されると、Auto Scalingのヘルスチェックで異常ありとみなされます。
2.1.2.ELBのヘルスチェック
Auto ScalingグループとELBを関連付けている場合にオプションで選択可能です。
ELB(CLB、ALB)は単体でヘルスチェック機能を有しており、そこでの評価を、Auto Scalingのヘルスチェックにも反映させることができます。それにより、「OSやインスタンスとしては正常だけれど、サービスが落ちている」といった、より細かいレベルでのヘルスチェックに対応可能となります。
AWSドキュメントの日本語訳に注意
2019/5/9時点のAWSドキュメントの記述より抜粋。
Auto Scaling グループへの Elastic Load Balancing ヘルスチェックの追加
Auto Scaling グループに 1 つ以上のロードバランサーまたはターゲットグループをアタッチしていると、デフォルトでは、グループはそのインスタンスを異常と見なさず、ロードバランサーのヘルスチェックに合格しない場合に置き換えます。
EC2のステータスチェックは評価対象外となり、ELBのヘルスチェックのみを評価する、と書いてあるようにも見えます。そんなことはありません。
If you attached one or more load balancers or target groups to your Auto Scaling group, the group does not, by default, consider an instance unhealthy and replace it if it fails the load balancer health checks.
正しく訳すなら以下のような形でしょうか。
『Auto Scaling グループに 1 つ以上のロードバランサーまたはターゲットグループをアタッチしている場合、デフォルトでは、ロードバランサーによるヘルスチェックに失敗したインスタンスがあったとしても、Auto Scalingグループにおける異常とはみなされず、置き換えも行われません。』
2.1.3.カスタムヘルスチェック
ユーザー側で独自に設定している監視と、ヘルスステータスをUnhealthyに遷移させるコマンドを組み合わせる方式です。
独自のヘルスチェックシステムがある場合、システムから Amazon EC2 Auto Scaling にインスタンスの状態情報を直接送信できます。
指定したインスタンスのヘルスステータスを Unhealthy に設定するには、次の set-instance-health コマンドを使用します。
aws autoscaling set-instance-health --instance-id i-123abc45d --health-status Unhealthy
例えばZabbixによる監視をおこない、独自に定義した条件に合致したら、連携したジョブ実行サーバからコマンドを発行してヘルスチェックに失敗させる、といったものです。Auto Scalingグループ内の個々のインスタンスで監視およびコマンド発行をしてもいいかもしれません。
2.3.発動時の挙動
Auto Scalingヘルスチェックに失敗したインスタンスを削除し、新たなインスタンスを新規作成します。それを置き換えと呼びます。
作成されるインスタンスは、起動設定で定義した内容(ベースとなるAMI、インスタンスタイプ、適用するセキュリティグループ、キーペア、ブロックデバイスマッピングなど)に従った設定値を持ちます。
2.4.保持されるデータ
基本的に無いと考えてください。
既存インスタンスの削除をして新規インスタンスの作成という挙動のためです。EC2インスタンスのIDやIPアドレスなども採番し直しとなります。
ただ、インスタンス削除後もアタッチされていたEBSボリュームは残しておく、という設定が可能なため、そこにデータが残る、という考え方はできます。
2.5.注意点
インスタンスの作り直しとなっても困らないように設計しておく必要があります。ユースケースによって千差万別ですが、例えば以下のようなものがあるでしょう。
- DB層を切り出して別のコンポーネントとしておく
- インスタンスがローンチされるタイミングでリポジトリからデータを取得する設定を入れておく
- 削除のタイミングでローカルに保持していたログを外部にアップロードする設定を入れておく
- Agentが実装されている場合は置き換え後にManagerとの通信を自動で再開できる設定としておく
また、新規作成されたインスタンスがヘルスチェックに正常に応答できるようになるまでの時間も考慮する必要があります。スケーリングパターンやELBとの組み合わせの有無によって、さまざま時間を設定できるパラメータが存在します。
3.Auto RecoveryとAuto Healingの差異比較
3.1.マトリクス
| 観点 | Auto Recovery | Auto Healing |
|---|---|---|
| 実行主体 | CloudWatchアラーム | Auto Scalingグループ |
| 実行契機 | StatusCheckFailed_Systemメトリクスのアラート遷移 | Auto Scalingヘルスチェックの失敗 |
| 実行契機のカバー領域 | 物理ホスト・ネットワークインフラ層 | 物理ホスト・ネットワークインフラ層からOS層まで(オプションでさらに詳細化が可能) |
| 発動時の挙動 | 仮想マシンの異なる物理ホストへのマイグレーション | EC2インスタンスの削除および新規作成による置き換え |
| 保持されるデータ | 基本的に、メモリ上にのみ存在したデータ以外すべて | 基本的になし |
| 注意点 | 発動にはいくつか条件がある。場合によって失敗する。 | インスタンスの置き換え後の挙動を想定した設計を行う必要がある。 |
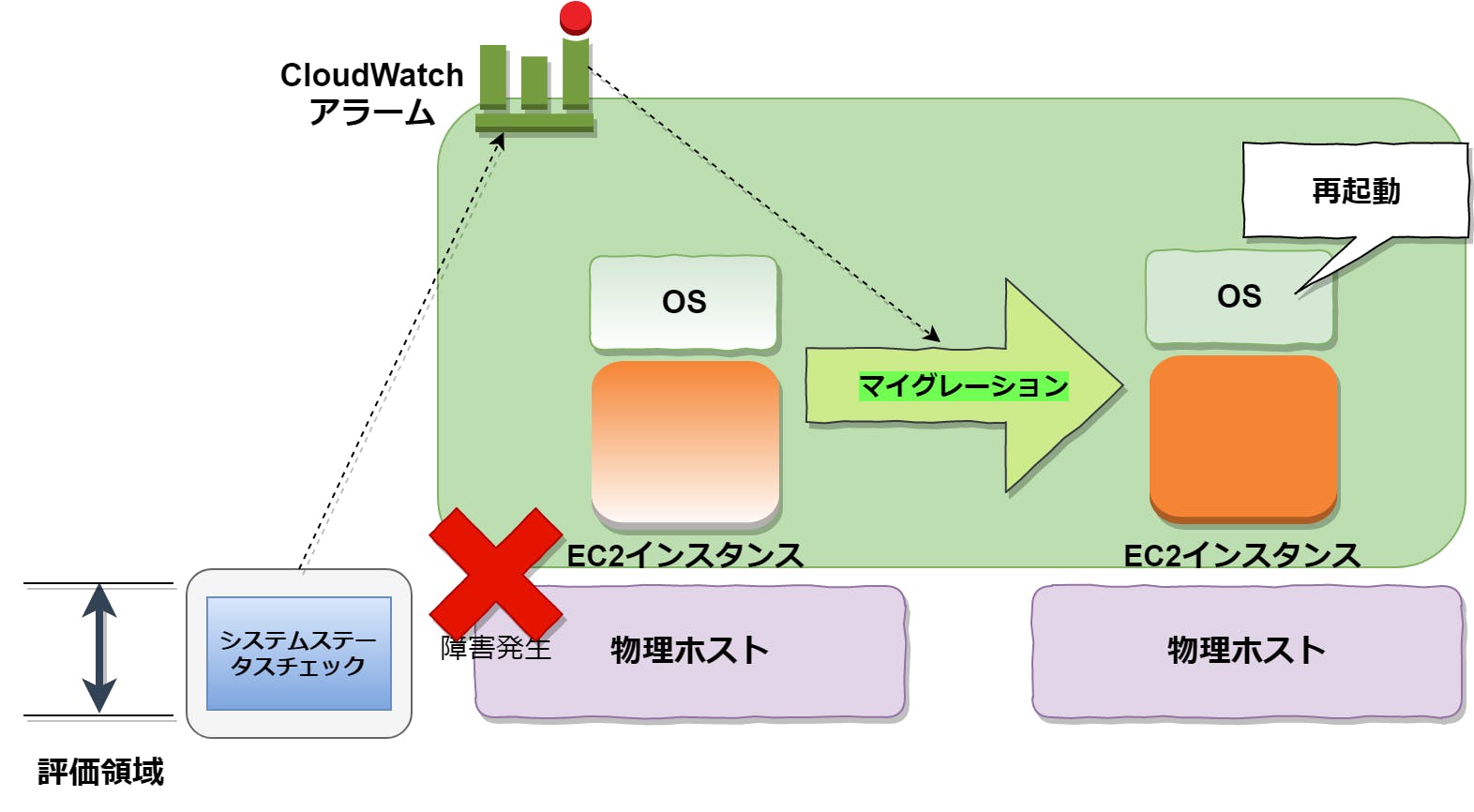
3.2.イメージ
Auto Recoveryのアーキテクチャのイメージ。
Auto Healingのアーキテクチャのイメージ。

おわりに
両者がまったく思想が異なるものだと理解いただけたでしょうか。
Auto Recoveryは基本的には「ひとまず有効化しておく」レベルの標準装備の印象です。一方でAuto Healingはかなりの設計を要するため、要件に見合っているかをよくよく検討する必要があるでしょう。
両者の特性を理解し、適切な対障害設計を行ってください。
