大変お世話になっております。pinocoです。
前回、抽象度の高いところでAthenaやAthenaの周辺環境について整理しました。
今回はとりあえず触ってみて、
どんな感じで設計すればいいかな、
ということを頑張ってまとめてみようと思います。
1.前回なんとなくわかったこと
・Athena自体の料金は「クエリごとにスキャンされたデータ量」で算出される(S3は別途通常の使用料金)
・Athenaのデータ処理はオンメモリで行われる
この2点からAthenaでクエリ発行時に読み込むデータ量を減らすアプローチが、
なんとなく性能的にも、お財布的にも優しそうである
ということがわかった気がしました。
では、とりあえずAthenaを動かしてみて
具体的にアプローチとして取れる手を整備していきたいと思います。
2.とりあえずAthenaの動作環境を整える
Athenaを実際に動かそうと思って一番最初に考えたのが
データをどう準備するかな、というものでした。
「public datasets」で、ざっと検索してみると
kaggleやAWS、なんならgithubにawesome-public-datasets
なんて言うOpenDataのまとめ情報もあり、
なんだかすごく助かるなーと言う気分になったのですが
後ろに控えているパーティション分割のことを考えると
割とどんなカラム持ってれば適合しそうか、2秒くらい悩みます。
なぜ2秒で済んでいるかと言うと、実は「どうしたらいいのかなー」から
ビタイチ思考が進まないため「どうしたらいいのかなー」→ timeout(2sec)と言う
絶望的な構造です。思考とは一体どう言う状態を指すのか再度捉え直したい、そう思いました。
でその末にTop Baby Names in the USを選択します
データ量としては約230KBなので、フルスキャンで10MB(10MB以下は切り上げ)
バッチ組んで延々フルスキャンするクエリを結構投げ続けるみたいなことをしなければ、
Athenaのクエリで私の財布が粉微塵に爆発四散阿鼻叫喚な自体は避けられるはずです(多分)
<余談>BigQueryだとドキドキを緩和するdry run(クエリ実行時の走査バイト数の確認)があった気がしましたが
Athenaだと何が該当しそうかすぐにはわかりませんでした。
じゃあ実際にS3に放り込んで、テーブル作ってクエリを投げてやったりましょう。
とりあえず事前に適当なバケットに先ほど取得したデータを放り込んでおきます。
AthenaのコンソールからCreateDataBaseが見つからないので
とりあえずCreate tableを選択すると、「[超訳]Glue使おうや、楽やで」と言う
表示が「手動でやるんや」と並んで出てきます。
が、Glueの利点を噛みしめるためにも、一度手動でいばらの道を通ってみます。
人生は選択の連続なのですね。
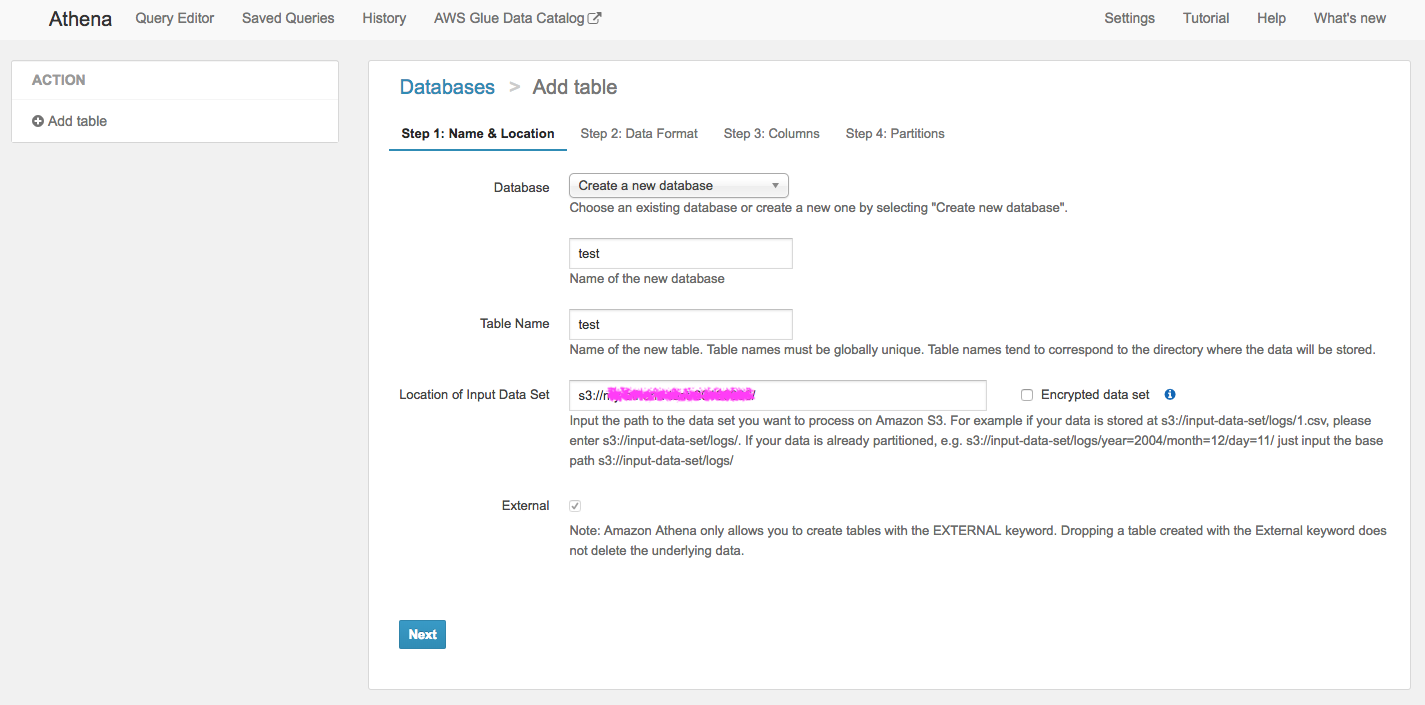
↓Databaseも新しく作って、先ほどのデータが入っているbucketを指定してテーブルを作成します。
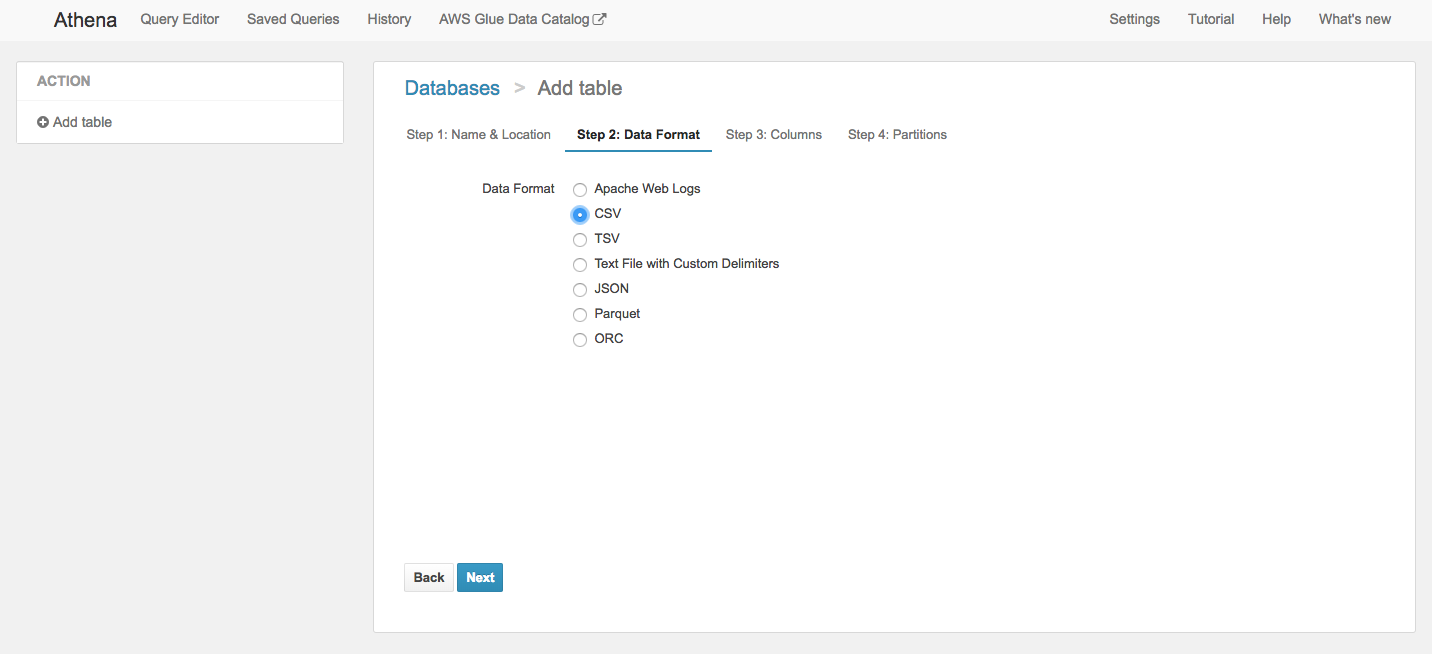
↓データはCSVなのでCSVを選択
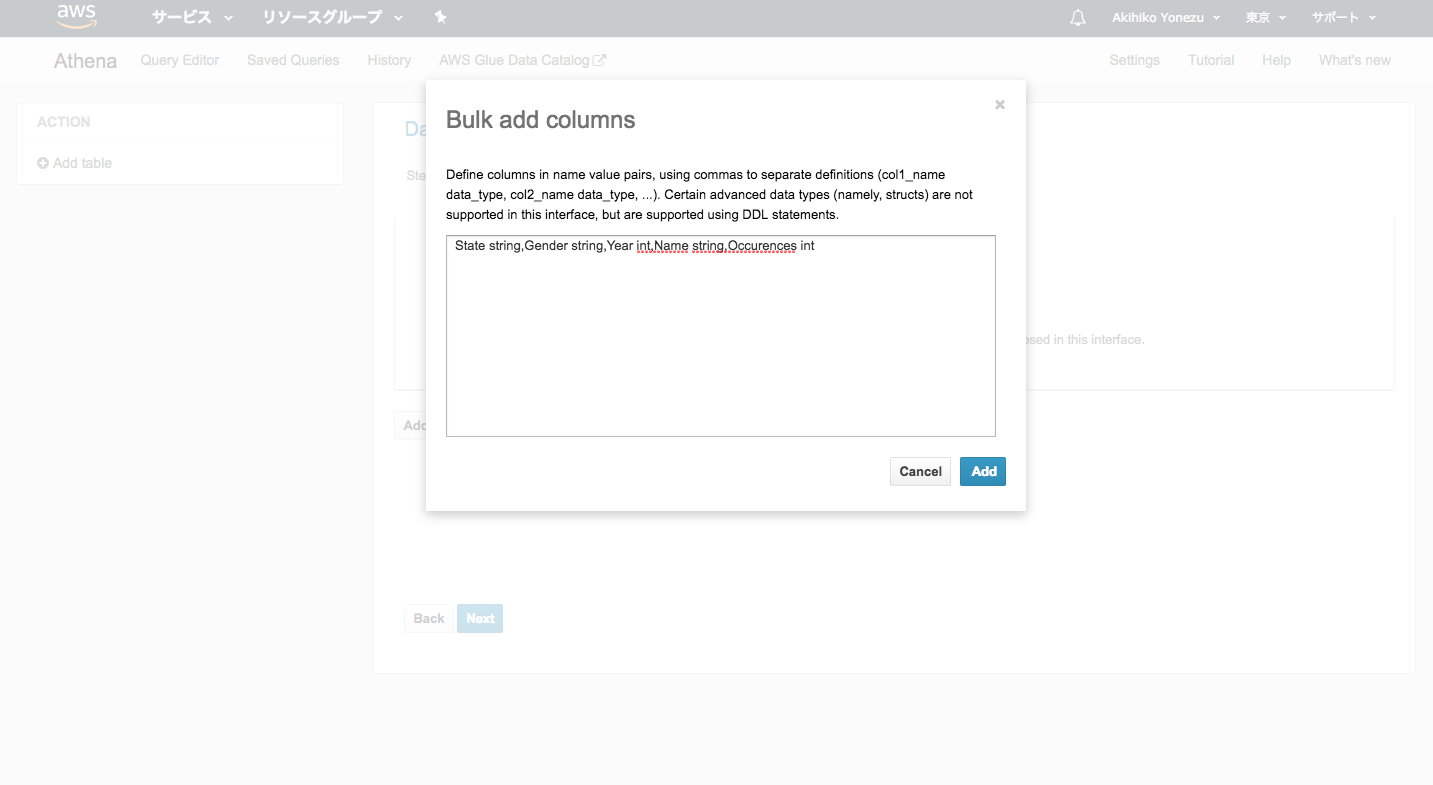
↓カラムは1個づつ定義できそうな画面だったのですが、Bulk addみたいなのがあったので、それで指定しました
↓最後にパーティション作成するかって感じの画面になりましたが、データがパーティションに適合した形式ではないためそのまま行きます
↓予想通りヘッダー行が入ってて、深くため息をつきます。
気をとり直して、ざっと作り直します。
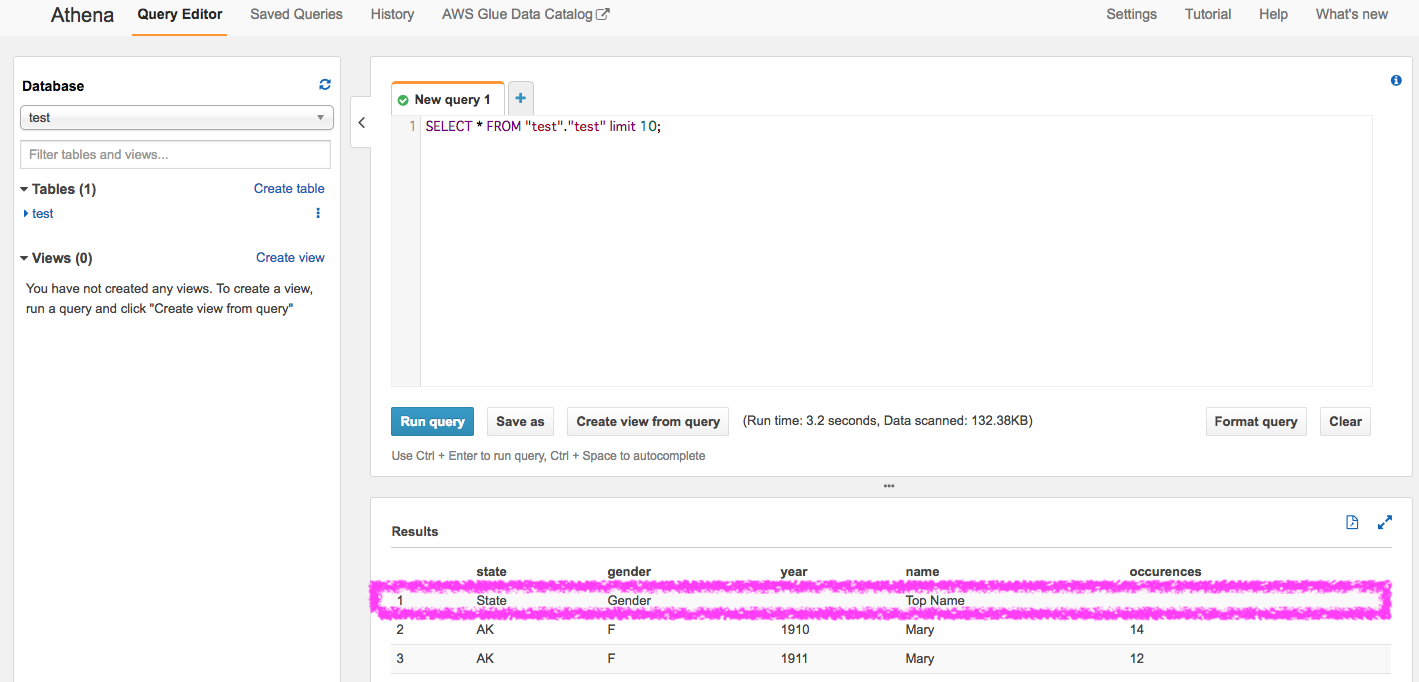
作り直した。※ヘッダ消して再度データファイルをuploadしてテーブル作り直し
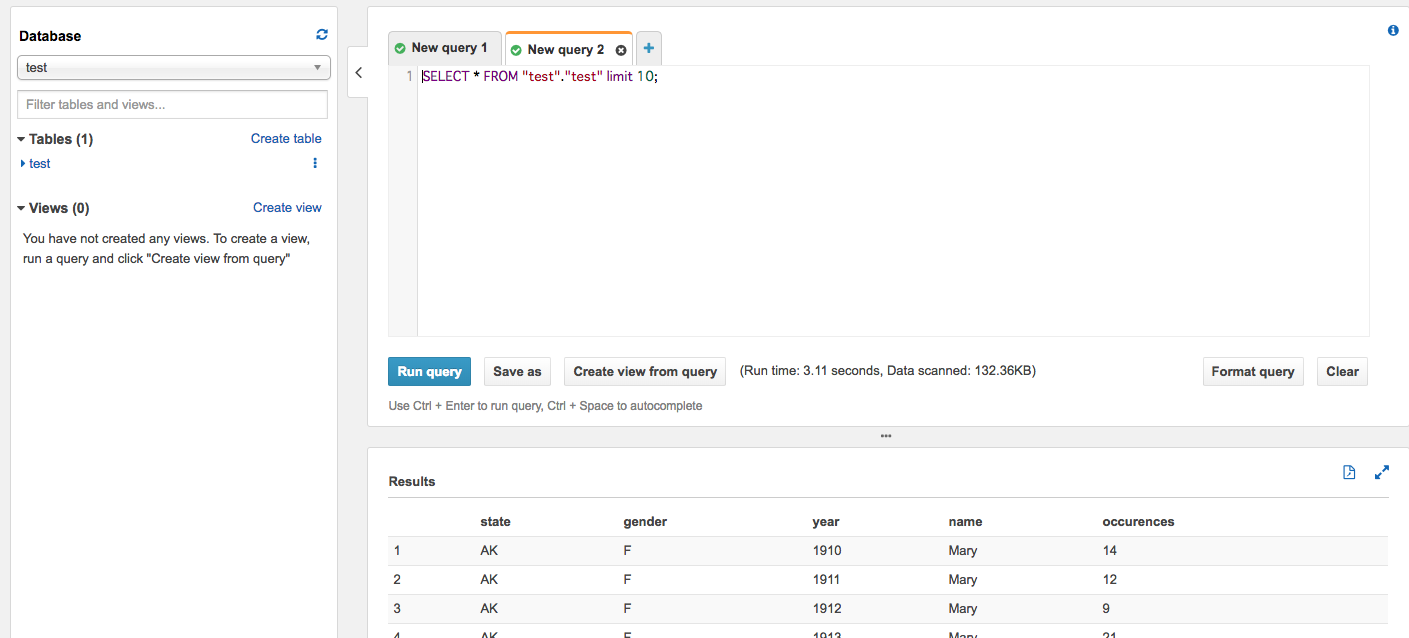
ようやく準備が整ったので、クエリを実際に投げてみようと思います。
私の生まれた年にどんな名前をつけるのが流行ったのかみてみます。
select name ,gender, sum(occurences) as summary from "test"."test" where year = 1983 group by name, gender order by summary desc
やー!
女の子はジェニファー、男の子はマイケルが入ってきました!
ここで3位にクリストファーがきているのもなかなか興味深いです。
画面中程にDataScannedとスキャンされたデータサイズが書いてありますが、
225.32KBになっているので、S3上に配置したcsvを全て読み込んでいるのがわかります。
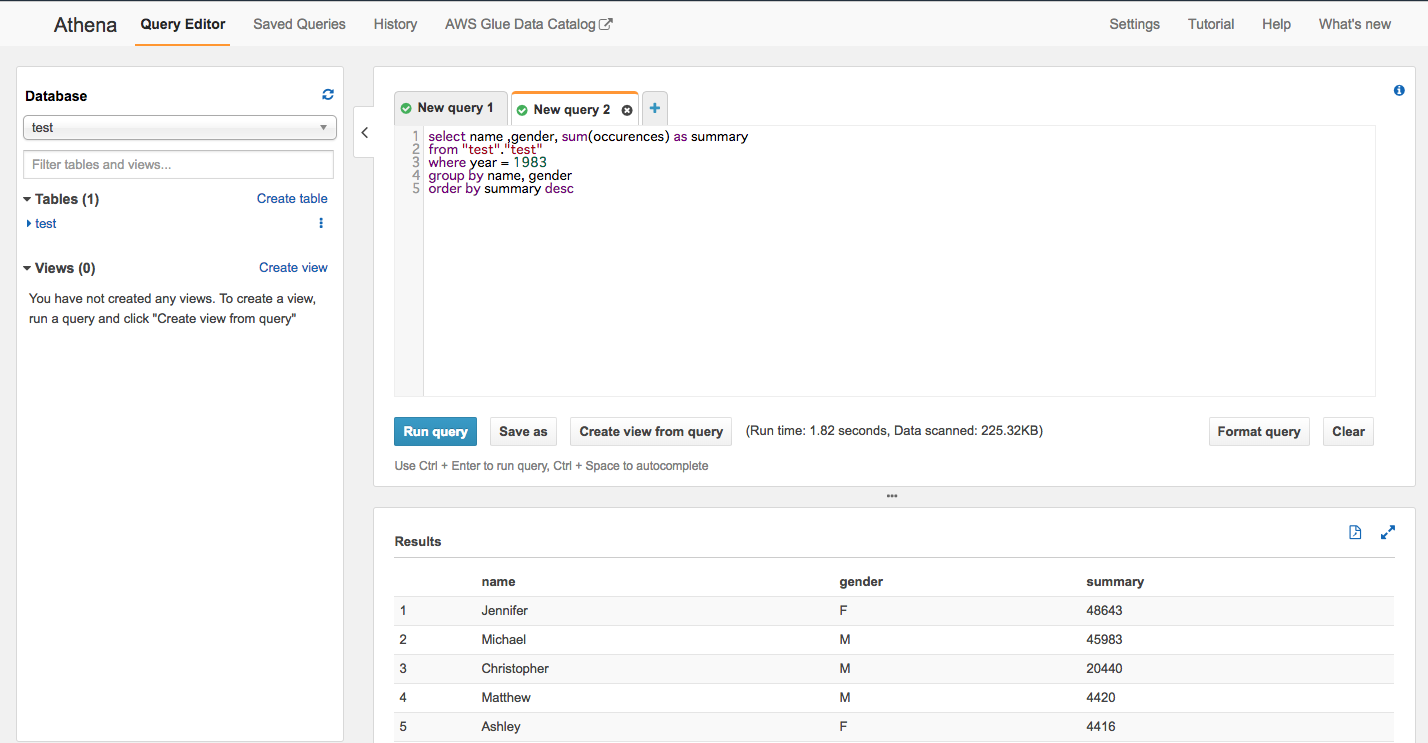
では州別で同じようにみてみましょう。
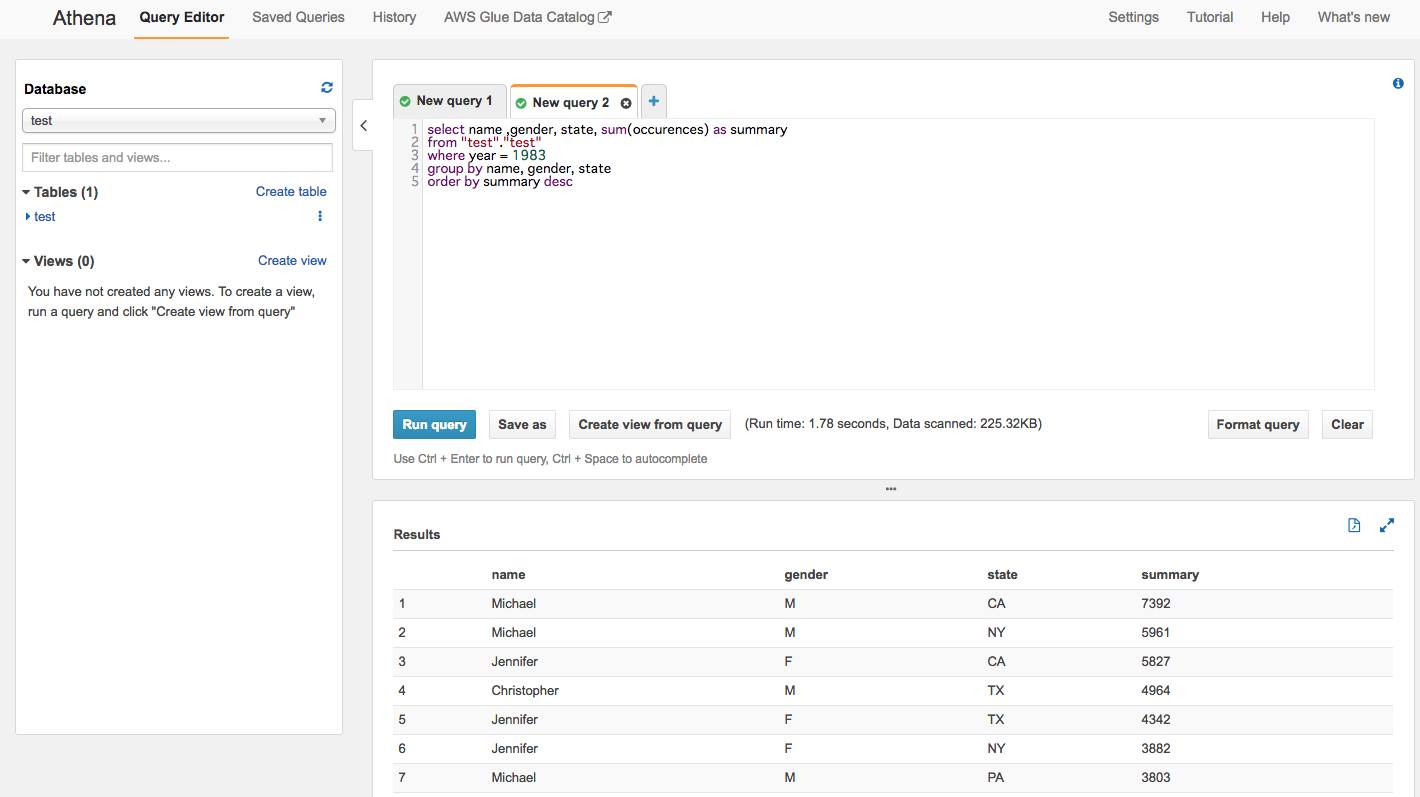
select name ,gender, state, sum(occurences) as summary from "test"."test" where year = 1983 group by name, gender, state order by summary desc
やー!
カリフォルニアとニューヨークでマイケル・ジェニファークラスタが強固な一方で、
テキサスでクリストファー勢が勃興していますね。
クリストファーといえばクリストファーウォーケンくらいしか思いつかないのですが、
おそるべしですね。
ああ。全然やりたいところまでたどり着けなかったんですが、
今日は、ここで時間切れなので、次回にパーティションのあたりを触って
設計に少しでも入れるといいなと思います。
つづく
