お世話になっております。pinocoです。
前回、S3上のデータファイルに対しAthenaでクエリを投げるところまでやりました。
今回はパーティションについて見て行きたいと思います。
1.Athenaのパーティションについて
データのパーティション分割
データをパーティション分割することで、各クエリでスキャンするデータの量を制限し、パフォーマンスの向上とコストの削減を達成できます。Athena では、データのパーティション分割に Hive を使用します。すべてのキーでデータをパーティション化できます。
らしいです。
みなさんどうです?この一文でどの程度、わかりましたでしょうか?
ちなみに私の絶望的な理解力では「便利がいいんだな」くらいでした。
それだけ書いて投稿して本件についてはCaseClose、塩漬けにする、と言う選択肢も
浮かばなかったといえば嘘になりますが
そうしてしまうとブログとして成り立たっていないばかりか
私は社内で石を投げられてしまいます。小石と言うには大きいほどの。
なので掘り下げるしかありますまいて。
2.実際にやってみる
何もない私には、この手しか残っていないわけで、
まずはやってみて、経過や結果から知識と徳を積んでいくスタイルです。
で、紆余曲折を経てなんとかなったわけなんですが、
混乱をもたらさないように先に結果を書いておきます。
(1). AtheneにおけるパーティションはS3上のデータをprefixで分割し、
その下にデータを分散配置させたものを認識させることで利用できます。
Hive形式で作成する場合だと[カラム名=値]と言う感じでS3のprefixを分割して行きます
e.g. s3://some-bucket/year=2016/some-data-file
/year=2015/some-data-file
このカラム名(上記例の場合year)がパーティションを切るためのキーとなります。
(2). パーティション分割に利用したキーはクエリを投げる際、
対象のテーブルのカラムとして認識されます
また(4)で触れますが基本的にWhere句に利用するカラムとなるため、
多く発行されそうなクエリからWhere句に利用されそうで、
かつなんとなく均等に分散され、スキャン時データサイズが大きくなりすぎない値を
パーティションに利用するキーとして選定すると良いと思います。ものすごく漠然としてますが。
(3). 上記(2)よりクエリを投げようと思っているデータ内
(と言うかそこから作ろうとしているテーブル)に、
存在するカラム名はパーティションのキーとしては利用できません。
(※)すごくわかりづらくてすみません。後続で補足します。
(4). パーティション作成で利用したカラムをWhere句で利用することにより、
S3のPrefixを限定したデータ走査が可能になります。
逆をいえばパーティションとして指定したカラムをWhere句で利用しない場合、
パーティションを切ってようが、いまいが
テーブルとして読み込む際に全ファイルを走査します。
"state","gender","year","name","occurences" "AK","F","2012","Emma","57" "AK","M","2012","James","51" "AL","F","2012","Emma","317" ・・・
#!/bin/bash input_fname=TopBabyNamesbyState.csv if [ ! -e $input_fname ]; then echo "[ERROR]:InputFile not Exist" exit 1 fi if [ ! -e output ]; then mkdir output fi y_ar=`q -H -d ',' "select distinct year from TopBabyNamesbyState.csv"` for i in $y_ar; do q -H -d ',' "select * from $input_fname where year = '$i'" > ./output/$i.csv aws s3 cp ./output/$i.csv s3://xxxxxxxx/year=$i/ done
10507 ./TopBabyNamesbyState.csv
10506 total
$
CREATE EXTERNAL TABLE IF NOT EXISTS test.test2 (
`state` string,
`gender` string,
`year` int,
`name` string,
`occurences` int
) PARTITIONED BY (
year int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://xxxxxxxx/'
TBLPROPERTIES ('has_encrypted_data'='false')
CREATE EXTERNAL TABLE IF NOT EXISTS test.song2 (
`state` string,
`gender` string,
`ys` int,
`name` string,
`occurences` int
) PARTITIONED BY (
year int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://xxxxxxx/'
TBLPROPERTIES ('has_encrypted_data'='false')
テーブル作成後は以下を同じ様にコンソールから実行しパーティション内のデータをロードするとあります。
MSCK REPAIR TABLE song2
Partitions not in metastore: ~ snip ~ Repair: Added partition to metastore song2:year=1910 Repair: Added partition to metastore song2:year=1911 ~ snip ~ Repair: Added partition to metastore song2:year=2011 Repair: Added partition to metastore song2:year=2012
ちなみにテーブル名はこの検証やってる時に社内に流れていたblurの曲名をつけてます。
(3).パーティションは効いているのか?確かめる
では実際に確かめて見ましょう。
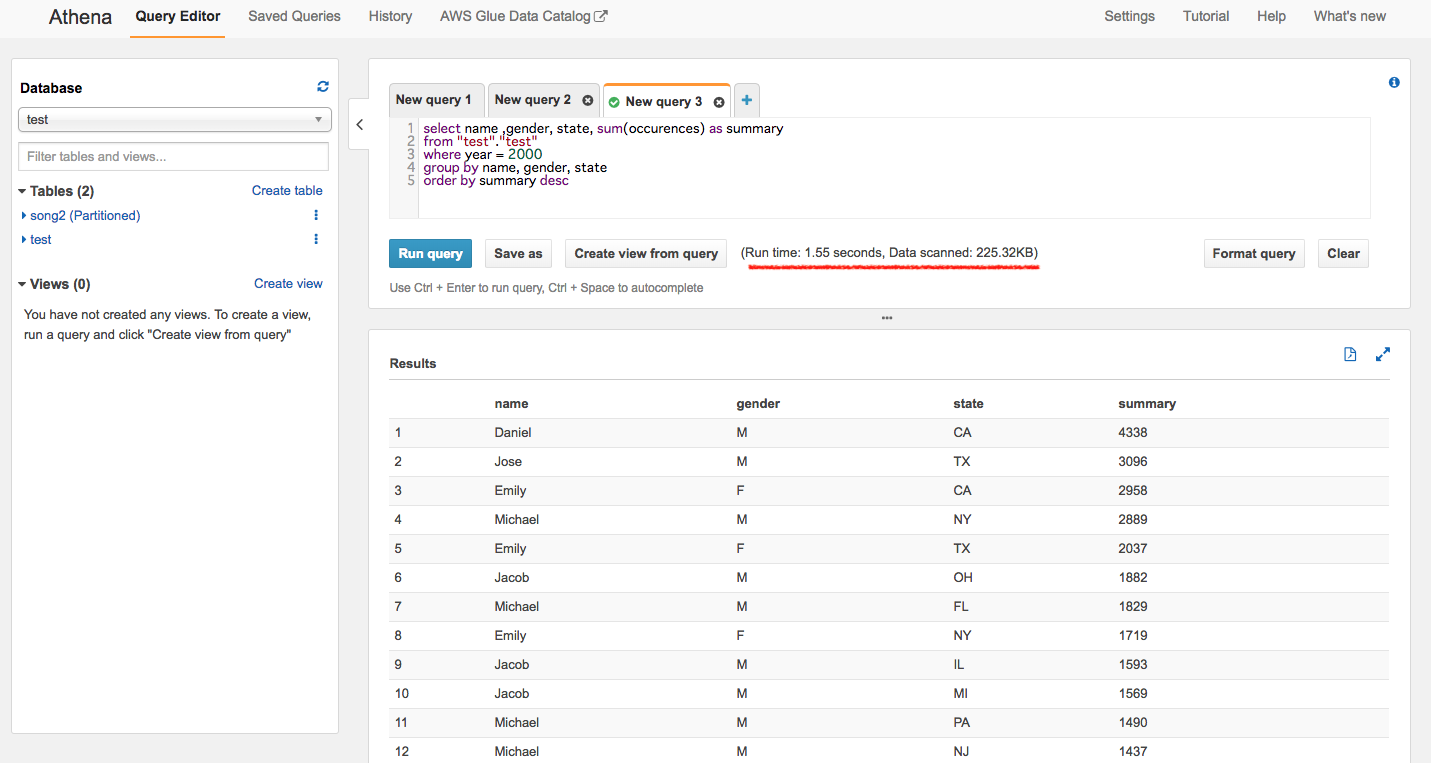
まずはパーティションを設定していない1つのCSVファイルに対しクエリを投げて見ます。
結果:RunTime:1.55 sec, DataScanned 225.32KB
フルスキャンしてますね。
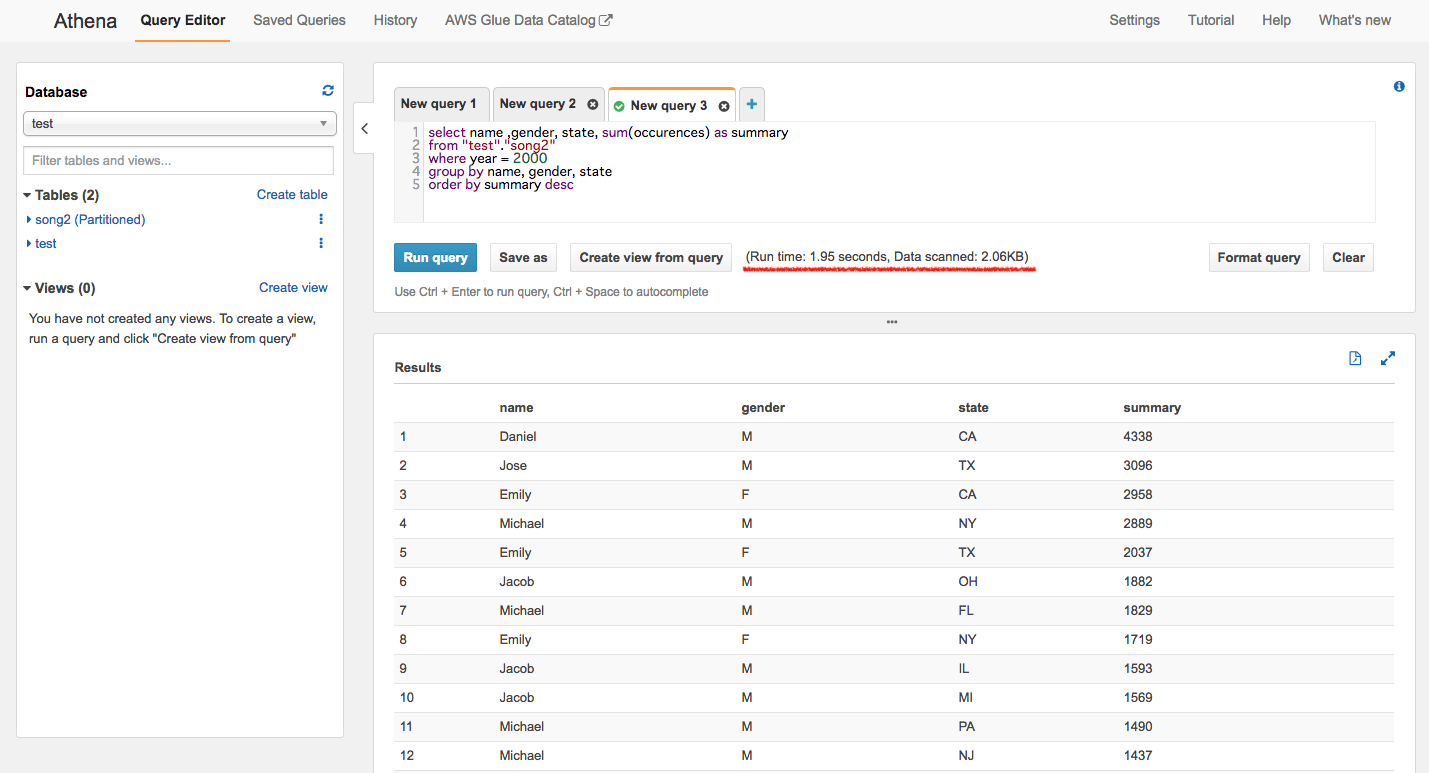
では次にパーティションで分割してるファイルにクエリを投げます。
結果:RunTime:1.95 sec, DataScanned 2.06KB
ん?RunTimeがさっきより長くなっとる気がします。
これはきっと小さいファイルを扱っているからパーティション処理周りのオーバーヘッドが
パーティション分割によるファイルスキャンの最適化の恩恵を上回ったのかなと、
大きいファイルにしたらいい線で改善するのでは、と勝手に推測しました。
ちなみにスキャンしたデータ量は100分の1程度でした。
1910年〜2012年のデータを年単位で分割したので、だいたい想定通りだと思います
パーティション効いてますねー
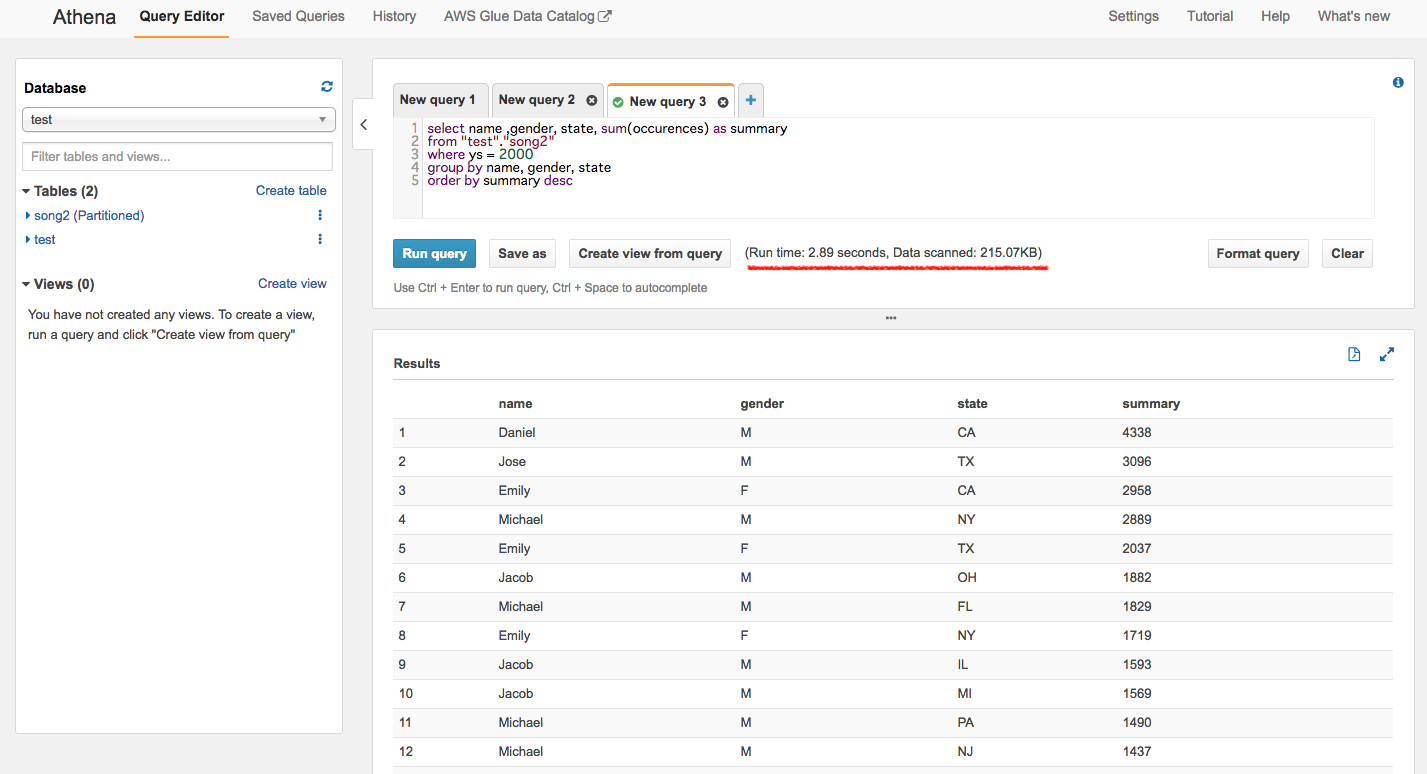
最後のパターンはパーティション分割済みのテーブルで「パーティションに使用したキー(カラム)をWhere句から外した」
パターンをやってみたいと思います。
結果:RunTime:2.89 sec, DataScanned 215.07KB
遅い上に全スキャンと言うなかなか香ばしい結果でした。
一番最初に実施した検証より7KB程少ないのですが、何処へ出かけたかはわかりません。
これで、Athenaのパーティションについての検証は終わりにしたいと思います。
今回のケースだと既に存在するファイルを取り回して検証しましたが、
ユースケース的にはログ解析とか多そうなので、そっち方面も時間があれば触ってみたいと思います。
次は、putするファイル形式で早くなるのか、とGlueでどう楽になるのか、についてを
お送りしたいと思います。
![[Auto Scaling]いつのまにか増えていたターゲットトラッキングポリシーを理解する](https://www.simpline.co.jp/wp-content/themes/sankakuya_skelton/img/noimage.png)